Generating Random Data in PostgreSQL
Dealing with randomness in PostgreSQL can be tricky. Sometimes we get a little bit unpredictable results. Sometimes the distribution of the random numbers is not what we wanted. Sometimes things are slow.
Here I’m trying to describe common problems I met when using PostgreSQL and how they can be solved.
PostgreSQL Random Functions
PostgreSQL has two basic functions for generating random data:
random()– returns a random value with uniform distribution from the range[0.0, 1.0)(includes0.0, but no1.0).setseed()– sets the internal value for the generator.
The algorithm used by the random() function generates pseudo-random values. It means that the next generated number depends on the generator’s internal state. The state is modified every time a number is generated and the new state depends on the previous one. The initial state can be set by the setseed() function. This kind of random number generation should be fine for most of the use cases.
Using the setseed() function is important for reproducible data generation. If you want to generate the same list of random numbers (fine, numbers which look like they are random) – you should set the initial state of the generator to the same value, right before generating the first number. This way you will get the same list of numbers every time. Check this example:
$ select random(), random(), random();
random | random | random
---------------------+---------------------+--------------------
0.00909462791863902 | 0.12934858223123769 | 0.7608317131370406
(1 row)
$ select setseed(1);
$ select random(), random(), random();
random | random | random
--------------------+-------------------+--------------------
0.4999104186659835 | 0.770017612227381 | 0.7111753978720401
$ select setseed(1);
$ select random(), random(), random();
random | random | random
--------------------+-------------------+--------------------
0.4999104186659835 | 0.770017612227381 | 0.7111753978720401
As you can see – after setting the internal generator state to the same value, the sequence of the generated random numbers is the same.
Generating Random Integer In a Range
Another useful function is generating a random integer in a given range. The standard random() function returns a number from a range of [0,1), this can be be used to generate a random integer in [min, max] (which includes the min and the max values).
There is a detailed discussion of the used formula and why a commonly used one is wrong, so here I will just show the code.
CREATE OR REPLACE FUNCTION
random_in_range(INTEGER, INTEGER) RETURNS INTEGER
AS $$
SELECT floor(($1 + ($2 - $1 + 1) * random()))::INTEGER;
$$ LANGUAGE SQL;
This function can be used as:
$ SELECT random_in_range(10, 19);
random_in_range
-----------------
11
(1 row)
We can also check if the distribution is really uniform:
SELECT random_in_range(10, 19) number, count(*)
FROM generate_series(1,1000*1000*100)
GROUP BY number
ORDER BY number ASC;
number | count
--------+----------
10 | 10002032
11 | 9998724
12 | 9997955
13 | 9998229
14 | 10001975
15 | 9998946
16 | 10006834
17 | 10001126
18 | 9997407
19 | 9996772
(10 rows)
Generating Random Floating Point Within Range
Making a random floating point number within a given range is a little bit more tricky. The problem is that the representation is not exact and it is possible that the generated number will be bigger than the maximum value.
Here is a simple function to generate such a number:
-- random_float_in_range(min, max)
CREATE FUNCTION random_float_in_range(
DOUBLE PRECISION,
DOUBLE PRECISION
)
RETURNS DOUBLE PRECISION
LANGUAGE SQL
AS $$
SELECT greatest($1, least($2, $1 + ($2 - $1) * random()));
$$;
This function is a little bit different:
greatest()– ensures that no returned value should be smaller than themin(I’m not sure it’s needed)least()– ensures that no returned value is bigger thanmax(this can happen, however, it’s quite unlikely)- the
random()function returns values within[min, max), so the returned value is in the range[min, max), themaxvalue can be achieved only as a side effect of adding floating point values
Generating Random String
There is a discussion of different implementations of functions generating random strings.
The winning implementation is:
-- random_text(length)
CREATE FUNCTION random_text(INTEGER)
RETURNS TEXT
LANGUAGE SQL
AS $$
select upper(
substring(
(SELECT string_agg(md5(random()::TEXT), '')
FROM generate_series(
1,
CEIL($1 / 32.)::integer)
), 1, $1) );
$$;
One drawback of this implementation is that it doesn’t use all the letters, it uses text generated from the md5() function, so the possible characters are: 0-9A-F.
I made benchmarks of the functions again to check how they work on the current PostgreSQL (v12) and on modern hardware. The slowest function is 4 times faster now. The fastest is 2 times faster.
The below times are also for 1k function calls.
| count | random_text_md5_v2[s] | random_text_simple[s] | random_text_simple_3[s] |
|---|---|---|---|
| 1 | 0.007784 | 0.003385 | 0.003266 |
| 5 | 0.008087 | 0.006208 | 0.005023 |
| 10 | 0.008075 | 0.010039 | 0.007346 |
| 50 | 0.008976 | 0.038539 | 0.018244 |
| 100 | 0.010587 | 0.074795 | 0.033005 |
| 500 | 0.022792 | 0.366925 | 0.15412 |
| 1000 | 0.034037 | 0.747121 | 0.303775 |
| 5000 | 0.152685 | 4.12288 | 1.51284 |
| 10000 | 0.30329 | 10.4067 | 3.01682 |
| 15000 | 0.438556 | 18.6102 | 4.59895 |
| 20000 | 0.594655 | 30.0483 | 6.0176 |
| 25000 | 0.728941 | 42.9524 | 7.51835 |
| 30000 | 0.876449 | 58.0902 | 9.03382 |
| 35000 | 1.03006 | 74.7604 | 10.5651 |
| 40000 | 1.17357 | 94.05 | 12.0875 |
| 45000 | 1.31703 | 115.326 | 13.5163 |
| 50000 | 1.44611 | 137.949 | 15.1363 |
| 55000 | 1.59372 | 164.231 | 16.8371 |
| 60000 | 1.75088 | 191.009 | 18.7902 |
I know, the md5_random_string is not the best thing for generating realistic texts. However, it’s quite fast. To have an efficient generation of realistic strings I’d make a PostgreSQL module written in C.
The old chart is:
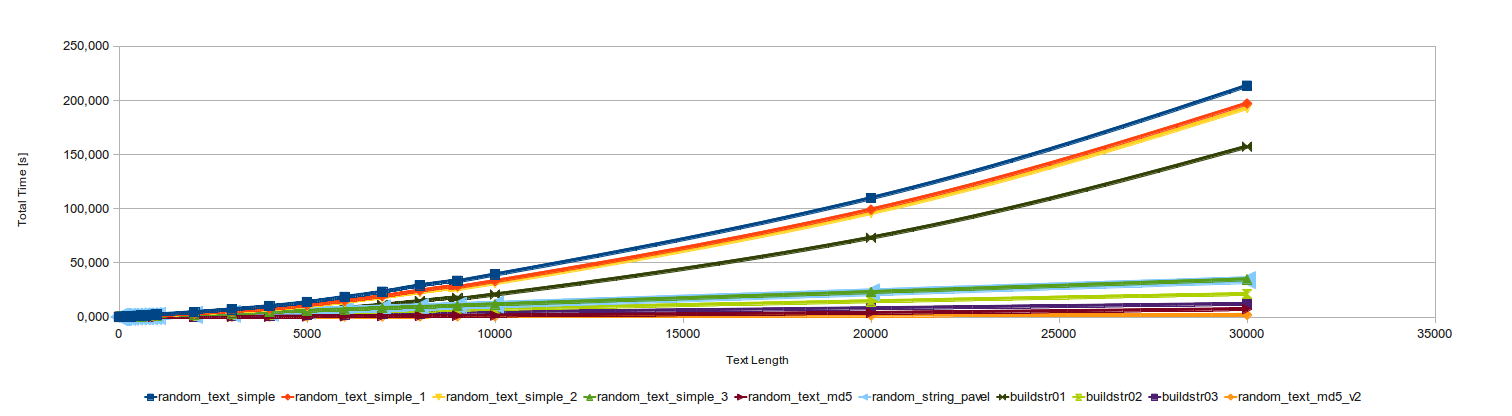
The current one is quite similar. It also looks nicer when you enlarge the page (as it’s an SVG file):

Generating Random UUID in PostgreSQL
“A universally unique identifier (UUID) is a 128-bit number used to identify information in computer systems.”
Unfortunately programmers too often think: “oh, it’s globally unique… so let’s use some random bits there”. This is terribly wrong.
There is a couple of variants of the UUID, in reality none of them is “universally unique”. However, one variant contains MAC address of the computer generating it, some time based values, and some random data. This is the version you want to use when generating values on different machines. The uniqueness of the generated UUIDs on one machine is guaranteed by the time part. The uniqueness between the machines is guaranteed by the uniqueness of the MAC addresses. Of course, you can change the time, you can change the MACs - just be careful.
There is also UUID Version 4, which is described as random. This doesn’t mean you can throw there 128 random bits.
Generating UUID From Random Bits in PostgreSQL
UUID is a 128-bit number, which also means 16 bytes. There is a hexadecimal form of a 16 bytes number where each byte is encoded using two hexadecimal digits (from 0 to 9 and from a to f). It is also generated from the md5() function, which wants text as input value. A very simple way to make a UUID with 128 random bits is:
SELECT md5(random()::TEXT)::UUID;
Generating Fully Random UUID From Time
You can also use time to generate the values. This way you can have e.g. the same generated value in a whole query even if you generate it a couple of times there. Or in a transaction. It can be useful.
To generate a UUID with 128 random bits from time, you can use this:
SELECT md5(now()::TEXT)::UUID;
Using the function now() can be a little bit tricky, as now() doesn’t return the current time, but the time of the beginning of the current transaction. Every single query run outside a transaction, runs inside it’s own. This way calling now() multiple times in a transaction or in the same query returns the same value:
BEGIN
*$ select now();
now
-------------------------------
2020-02-13 14:05:02.334247+01
*$ select now();
now
-------------------------------
2020-02-13 14:05:02.334247+01
*$ rollback;
ROLLBACK
$ select now(), pg_sleep(5), now();
now | pg_sleep | now
-------------------------------+----------+-------------------------------
2020-02-13 14:05:24.216538+01 | | 2020-02-13 14:05:24.216538+01
(1 row)
This can be useful or can be problematic. If you want to generate a totally random UUID every time, it’s better to use:
BEGIN
*$ select md5(clock_timestamp()::TEXT)::UUID
from generate_series(1,5);
md5
--------------------------------------
6178850f-985e-a884-13fc-027a547b8d57
83840b7b-acad-cdb2-78cf-6db3af38e056
4501c183-6d03-9a4a-97ba-1f92d2bc6ae3
c89beed0-6d0d-09eb-747e-a1838f9c60fe
b191f6c6-45f8-7194-2f0e-a7ca28c4613e
(5 rows)
Generating Good UUID v4
This is a common way to generate a random UUID, which is unfortunately quite wrong, and can cause problems. If in you application all the UUIDs are validated, then the above ones will not pass. The validation must go a little bit further than having just fully random set of 128 bits.
UUID standard defines that there are specific bits which indicate the version of the UUID. The rest can be generated using some other methods, including using a random number generator:
A version 4 UUID is randomly generated. As in other UUIDs, 4 bits are used to indicate version 4, and 2 or 3 bits to indicate the variant (102 or 1102 for variants 1 and 2 respectively). Thus, for variant 1 (that is, most UUIDs) a random version-4 UUID will have 6 predetermined variant and version bits, leaving 122 bits for the randomly generated part, for a total of 2122, or 5.3×1036 (5.3 undecillion) possible version-4 variant-1 UUIDs. There are half as many possible version-4 variant-2 UUIDs (legacy GUIDs) because there is one less random bit available, 3 bits being consumed for the variant.
https://en.wikipedia.org/wiki/Universally_unique_identifier#Version_4_(random)
The best way to generate the Version 4 UUID (aka The Random UUID) is to use a function which sets the proper bits. In PostgreSQL these functions are in two places:
uuid_generate_v4()from theuuid-osspmodulegen_random_uuidfrom thepgcryptomodule
CREATE EXTENSION "uuid-ossp";
$ SELECT uuid_generate_v4() FROM generate_series(1,10);
uuid_generate_v4
--------------------------------------
ec067aae-5fe3-4a23-8b3d-5f5dcca818fb
b8e51f6b-7baf-4234-a77e-f838e96cb494
af762d82-acd3-49ee-9e2d-3c1e3d8d8793
fe9de521-94a5-4a2f-9694-8997d4c74a71
f4fb17bf-59ba-485d-bea6-fe4666289896
bb68dfd1-73c8-4870-8dee-b64235f94221
549b87fc-e606-4155-af08-f03752aa2768
40ec40f7-ec00-45f5-8ea3-d86b0a768c2c
753fa40c-7396-4710-bee5-7d69f2b5dfdb
240c5261-c8fb-4e2a-a92f-5269ca26e1f5
(10 rows)
CREATE EXTENSION pgcrypto;
$ SELECT gen_random_uuid() FROM generate_series(1,10);
gen_random_uuid
--------------------------------------
d3905715-26e8-4abc-9b42-a5a194635d53
d914d4eb-4691-46e4-b0f7-252bca1aa2e2
760191dc-3f17-496b-8f78-bd9fcf24c421
d23f9668-27fb-45bf-983f-57d44bcb289a
75747212-f8eb-4ab8-b47a-03f31a1c6824
c80b9721-6ab6-42b7-8fbc-1393e2aa459c
734c149d-6db5-4e6c-821c-e6eb7dba8b78
105a5ea5-1589-40ac-9391-cd97a01945c3
46a6c1ef-42e2-471a-832b-8a1f215543b6
9e3ad8ed-fa29-4826-b151-25138b6d6a2f
(10 rows)
As you can see, all the values are in the format of xxxxxxxx-xxxx-4xxx-xxxx-xxxxxxxxxxxx where the 4 is the indicator of the UUID version.
Selecting Random Row From Table
Another interesting thing is selecting a random row from a table. Let’s make a huge table:
CREATE TABLE test(id serial primary key, t text);
INSERT INTO test(t)
SELECT g::TEXT FROM generate_series(1,1000*1000*10) g;
$ SELECT
count(*)/1000/1000 "Row Count [M]",
pg_size_pretty(pg_relation_size('test'))
FROM test;
Row Count [M] | pg_size_pretty
---------------+----------------
10 | 422 MB
(1 row)
Now let’s do two things:
- select one random row
- select ten random rows
The most common solution is to use order by random():
SELECT * FROM test ORDER BY random() LIMIT 1;
SELECT * FROM test ORDER BY random() LIMIT 10;
This is a very simple solution, which works great… in tests, on slides, and trainings. The problem appears when a table is huge enough. These queries are terribly slow.
Check the plan:
$ EXPLAIN ANALYZE SELECT * FROM test ORDER BY random() LIMIT 1;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------
Limit (cost=229050.26..229050.26 rows=1 width=19) (actual time=2203.580..2203.582 rows=1 loops=1)
-> Sort (cost=229050.26..254049.72 rows=9999786 width=19) (actual time=2201.898..2201.898 rows=1 loops=1)
Sort Key: (random())
Sort Method: top-N heapsort Memory: 25kB
-> Seq Scan on test (cost=0.00..179051.32 rows=9999786 width=19) (actual time=0.031..1043.446 rows=10000000 loops=1)
Planning Time: 0.044 ms
JIT:
Functions: 3
Options: Inlining false, Optimization false, Expressions true, Deforming true
Timing: Generation 0.352 ms, Inlining 0.000 ms, Optimization 0.113 ms, Emission 1.473 ms, Total 1.938 ms
Execution Time: 2203.982 ms
As you can see: there is no optimisation, getting one row takes over 2s. The problem is that the database needs to go through all the rows and call the random() function for each of them. Then order all the rows ( using these values) and get the first one. The bigger the table is, the worst the time is.
This kind of query cannot be easily indexed. We cannot have an index storing a random number for each row as CREATE INDEX x ON TEST (random()) will not work. The random() function is not marked as IMMUTABLE, which means that it can return different value every time it’s called. Yea, it makes sense for this function. However, indices need something different.
Of course, we can have an additional column with default=random(). However, I think that adding this kind of artificial column only to get one query working is too big change for the data schema.
One simple implementation of order by random is selecting one random id. We cannot just choose an id value from the range of [min(id), max(id)] as there can be wholes and, in a general case, such a function could run for a long time.
A simple algorithm can be: get a random number from the range of [min(id), max(id)] and then get the first id bigger or equal this number.
SELECT *
FROM test
WHERE id >= (
SELECT random_range(
(SELECT min(id) FROM test),
(SELECT max(id) FROM test)
)
)
ORDER BY id ASC
LIMIT 1;
And this is pretty fast, as the id column is already indexed. Now it runs for 0.4 ms on my computer.
To get 10 rows we should call this query 10 times. However, it is possible that an id will be chosen more than once, this way it should be chosen again. It is also possible that the number of request rows is so close to the number of possible rows from the table, that an already chosen id will be taken again and again. In this case there should also be a check for this.
It is also possible that you don’t use a simple integer id for your primary key. You can have a primary key combined from multiple columns or something else like a string or UUID. In this case getting a random row is a little bit more complicated. For such a case I’d suggest using an additional integer column from a generator and then do the above query.
Generating Random Date Within a Range
Dates can also be generated randomly. You can always add 1 to any date and you will get the date of the next day. The below function generates a random date between the given arguments (inclusive at both ends). The main idea is to calculate the time difference between the ranges and then use it to generate the random integer added to the starting date.
-- random_date_in_range(min, max)
CREATE FUNCTION random_date_in_range(DATE, DATE)
RETURNS DATE
LANGUAGE SQL
AS $$
SELECT $1 + floor( ($2 - $1 + 1) * random() )::INTEGER;
$$;
Generating Random Timestamp Within a Range
Timestamps are a little bit more complicated, you cannot just add 1 to it. You need to specify if the added value is a second, a minute, an hour.
Generating a random timestamp within a given range can be done using the below function:
-- random_timestamp_in_range(min, max)
CREATE FUNCTION random_timestamp_in_range(TIMESTAMP, TIMESTAMP)
RETURNS TIMESTAMP
LANGUAGE SQL
AS $$
SELECT $1 + floor(
( extract(epoch FROM $2 - $1) + 1) * random()
)::INTEGER::TEXT::INTERVAL;
$$;
Generating Random Value In Subquery
There is one small problem when using all the above functions in a subquery. More information can be found at one of my previous posts.
Check this query:
SELECT
random_in_range(1,10),
(SELECT random_in_range(1,10))
FROM generate_series(1,10) g;
random_in_range | random_in_range
-----------------+-----------------
5 | 7
10 | 7
1 | 7
3 | 7
2 | 7
6 | 7
7 | 7
3 | 7
7 | 7
3 | 7
The problem is that:
It turned out that PostgreSQL can treat such a scalar subquery, which doesn’t have any outer dependencies as a stable one, so it can be evaluated only once. It is evaluated only once even if the function used in the subquery is marked as volatile.
The solution is to make some external dependency in the subquery, even as simple as this one:
SELECT
random_in_range(1,10),
(SELECT random_in_range(1,10) WHERE g=g)
FROM generate_series(1,10) g;
random_in_range | random_in_range
-----------------+-----------------
8 | 3
6 | 9
1 | 8
9 | 5
3 | 2
5 | 9
3 | 5
5 | 9
8 | 2
1 | 8