Random String in PostgreSQL
Last time I wrote about common problem with the random function. PostgreSQL has only the random(). There is no function like random(from, to) or random(length), which returns a random text of the given length.
This time I just needed a function which returns a random text of the given length. Then it can be used like this: SELECT random_text(42). The random text will be used as a slug in a web application, so I need only numbers and letters and let’s also have only uppercase.
Let’s create a PL/pgSQL procedure for returning a random text with the given length.
A Naive Solution
There is a very common solution to that problem: take an array of characters and choose randomly from them. Something like this:
CREATE OR REPLACE FUNCTION random_text_simple(length INTEGER)
RETURNS TEXT
LANGUAGE PLPGSQL
AS $$
DECLARE
possible_chars TEXT := '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ';
output TEXT := '';
i INT4;
pos INT4;
BEGIN
FOR i IN 1..length LOOP
pos := random_range(1, length(possible_chars));
output := output || substr(possible_chars, pos, 1);
END LOOP;
RETURN output;
END;
$$;
Looks great. The only thing missing there is the function random_range.
The function I use looks like this:
CREATE OR REPLACE FUNCTION random_range(INTEGER, INTEGER)
RETURNS INTEGER
LANGUAGE SQL
AS $$
SELECT ($1 + FLOOR(($2 - $1 + 1) * random() ))::INTEGER;
$$;
The idea behind this function is described in one of my older posts: common problem with random min max.
Let’s check the efficiency of the function. How much time does it take to run it 1k times with different parameters:
param time [s]
---------------------------------- -------------------------------------
1 0.013
2 0.013
10 0.052
50 0.115
100 0.223
1,000 2.224
10,000 39.885
30,000 217.746
One question. Does that look OK? Maybe not OK? If not OK, then why is that bad? Times are bad… but compared to what?
A One Step Better Solution
How to improve the function? My first idea was to get rid of the variable pos and inline it into the next line. After such a change the function is:
CREATE OR REPLACE FUNCTION random_text_simple_1(length INTEGER)
RETURNS TEXT
LANGUAGE PLPGSQL
AS $$
DECLARE
possible_chars TEXT := '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ';
output TEXT := '';
i INT4;
BEGIN
FOR i IN 1..length LOOP
output := output || substr(possible_chars, random_range(1, length(possible_chars)), 1);
END LOOP;
RETURN output;
END;
$$;
What about the timings?
param time [s] previous [s]
-------------------- ---------------------- ----------------------------
1 0.010 0.013
2 0.011 0.013
10 0.024 0.052
50 0.087 0.115
100 0.168 0.223
1,000 1.677 2.224
10,000 34.677 39.885
30,000 199.434 217.746
Looks a little bit better. Not bad, but could we do some more about that?
A One Step Better Solution
My second try was to calculate the length of the string before the loop. Maybe PL/pgSQL can optimize that, maybe not, I will check.
Here is the function and timings:
CREATE OR REPLACE FUNCTION random_text_simple_2(length INTEGER) RETURNS TEXT LANGUAGE PLPGSQL
AS $$
DECLARE
possible_chars TEXT := '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ';
output TEXT := '';
i INT4;
chars_size INTEGER := length(possible_chars);
BEGIN
FOR i IN 1..length LOOP
output := output || substr(possible_chars,
random_range(1, chars_size), 1);
END LOOP;
RETURN output;
END; $$;
param time [s] previous [s]
-------------------- ---------------------- ----------------------------
1 0.011 0.010
2 0.012 0.011
10 0.023 0.024
50 0.081 0.087
100 0.153 0.168
1,000 1.496 1.677
10,000 32.353 34.677
30,000 193.639 199.434
This doesn’t seem to be a big gain compared to the second one.
A One Step Better Solution
Another idea was to inline the random_range function.
CREATE OR REPLACE FUNCTION random_text_simple_3(length INTEGER)
RETURNS TEXT
LANGUAGE PLPGSQL
AS $$
DECLARE
possible_chars TEXT := '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ';
output TEXT := '';
i INT4;
chars_size INTEGER;
BEGIN
chars_size := length(possible_chars);
FOR i IN 1..length LOOP
output := output || substr(
possible_chars,
(1 + FLOOR((chars_size - $1 + 1) * random() ))::INTEGER, 1);
END LOOP;
RETURN output;
END; $$;
param time [s] previous [s]
-------------------- ---------------------- ----------------------------
1 0.011 0.011
2 0.012 0.012
10 0.023 0.023
50 0.069 0.081
100 0.127 0.153
1,000 1.172 1.496
10,000 11.672 32.353
30,000 35.028 193.639
Wow. I’ve never thought that inlining such a simple function would give me so huge difference.
The Best Solution… So Far
While I was thinking about the cons of PL/pgSQL, I thought about writing the code in C and just use a C library.
Then I thought about using something strange like md5(random()::TEXT). The whole idea behind this solution is to use two functions written in C. There will be some PL/pgSQL glue code, but the whole logic would be
written in C.
The algorithm is:
- Calculate the number of MD5 sums to get at least
lengthchars.- Call
md5(random())code and concatenate the results.- Use
substring()andupper()for the final result.
The function for the above algorithm:
CREATE OR REPLACE FUNCTION random_text_md5(length INTEGER)
RETURNS TEXT
LANGUAGE PLPGSQL
AS $$
DECLARE
-- how many md5's we need to have at least length chars
loop_count INTEGER := CEIL(length / 32.);
output TEXT := ''; -- the result text
i INT4; -- loop counter
BEGIN
FOR i IN 1..loop_count LOOP
output := output || md5(random()::TEXT);
END LOOP;
-- get the substring for the exact number of characters
-- and upper them up
RETURN upper(substring(output, length));
END; $$;
Nothing special, it just works. What about the timing? The timing will be a little bit later.
The SQL Version
Pavel wrote a very interesting comment about using a pure SQL function. I’ve changed his function a little bit and the new function looks like this:
CREATE OR REPLACE FUNCTION random_string_pavel(int)
RETURNS text
AS $$
SELECT array_to_string(
ARRAY (
SELECT substring(
'0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ'
FROM (random() *36)::int FOR 1)
FROM generate_series(1, $1) ), '' )
$$ LANGUAGE sql;
Additional SQL Functions
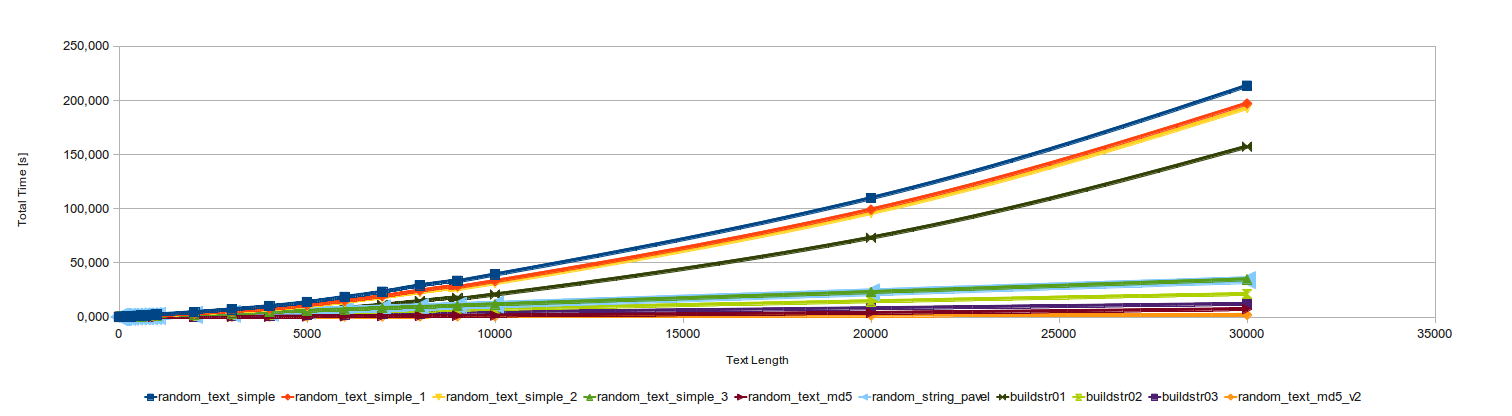
The timings for the new function were added to the below table. The chart has been updated.
Pavel posted three other versions of that function. The code is in the comment below, so I won’t place it here. I’ve run the tests once again for all the functions. The below data and charts have been updated.
My md5 version is still the best.
Combined md5 And SQL
Pavel also suggested combining the md5 version and the buildstr03. I’ve created the below version:
CREATE OR REPLACE FUNCTION random_text_md5_v2(INTEGER)
RETURNS TEXT
LANGUAGE SQL
AS $$
select upper(
substring(
(SELECT string_agg(md5(random()::TEXT), '')
FROM generate_series(
1,
CEIL($1 / 32.)::integer)
), 1, $1) );
$$;
This is the best solution so far, thanks Pavel. It is twice faster than the old md5 version.
Final Results
| length of text | simple | simple_1 | simple_2 | simple_3 | md5 | md5_v2 |
|---|---|---|---|---|---|---|
| 1 | 0.013 | 0.010 | 0.011 | 0.011 | 0.023 | 0.039 |
| 2 | 0.013 | 0.011 | 0.012 | 0.012 | 0.018 | 0.033 |
| 10 | 0.030 | 0.024 | 0.023 | 0.023 | 0.017 | 0.034 |
| 50 | 0.115 | 0.087 | 0.081 | 0.069 | 0.020 | 0.036 |
| 100 | 0.223 | 0.168 | 0.153 | 0.127 | 0.025 | 0.041 |
| 1,000 | 2.244 | 1.677 | 1.496 | 1.172 | 0.106 | 0.098 |
| 10,000 | 39.885 | 34.677 | 32.353 | 11.672 | 1.462 | 0.672 |
| 30,000 | 217.746 | 199.434 | 193.639 | 35.028 | 7.448 | 1.962 |
And the chart for this.
Final Notes
PL/pgSQLis not very efficient, but can be easily improved- functions are not inlined and calls are expensive (but inlining by copying is not the best idea)
- the fastest way is to use some functions written in C
- I think the fastest way would be to use some function written in C
- Interesting thing is that the last two functions scale linearly when the text size increases.
- Pavel’s suggestions with the
SQLfunction has the same timings as myrandom_test_simple_3- Another Pavel’s suggestion resulted in the best version
random_text_md5_v2- The best solution
random_text_md5_v2is 12 times faster than the bestPL/pgSQLsolution.